- Published on
Increasing Chatbot Accuracy by Auto-Matching Prompts with Suitable AI Models

Welcome to theUbik Blog!
If you haven’t already subscribed, subscribe here!
Different models have different strengths
As heavy AI users, we constantly bounce between different subscription-based platforms like ChatGPT, Claude, and Gemini to complete various tasks.
Not only is this annoying - it is expensive. **
**There are many useful ( but pricey) AI models, each offering distinct capabilities. Choosing one can be difficult; it's like picking a smartphone based on camera quality—they're all similar, but only an expert can tell the difference.
We builtPreCog to simplify this process by automatically selecting the most suitable model for any task. This allows for focusing on achieving goals efficiently and creatively without being locked into one chatbot experience.
What makes PreCog different?
PreCog isn’t just one model or AI chatbot, instead PreCog acts as an AI “middleman”, directing/matching prompts to the most suitable AI model based on the models strengths and weaknesses relative to the users query.
AI Model Matchmaking: PreCog automatically selects the most appropriate AI model for each request. This feature conserves time and enhances the accuracy of generated responses.
Versatile Assistance: PreCog is adaptable to various tasks, from coding projects to creative writing. It provides reliable support for diverse needs and ensures the availability of the right tools for multiple applications.
Continuous Model Improvements: PreCog incorporates the most recent advancements in AI technology by utilizing models informed by the latest LLM leaderboard. This ongoing improvement ensures that users experience an up-to-date and efficient AI service.
PreCog Model Leaderboard
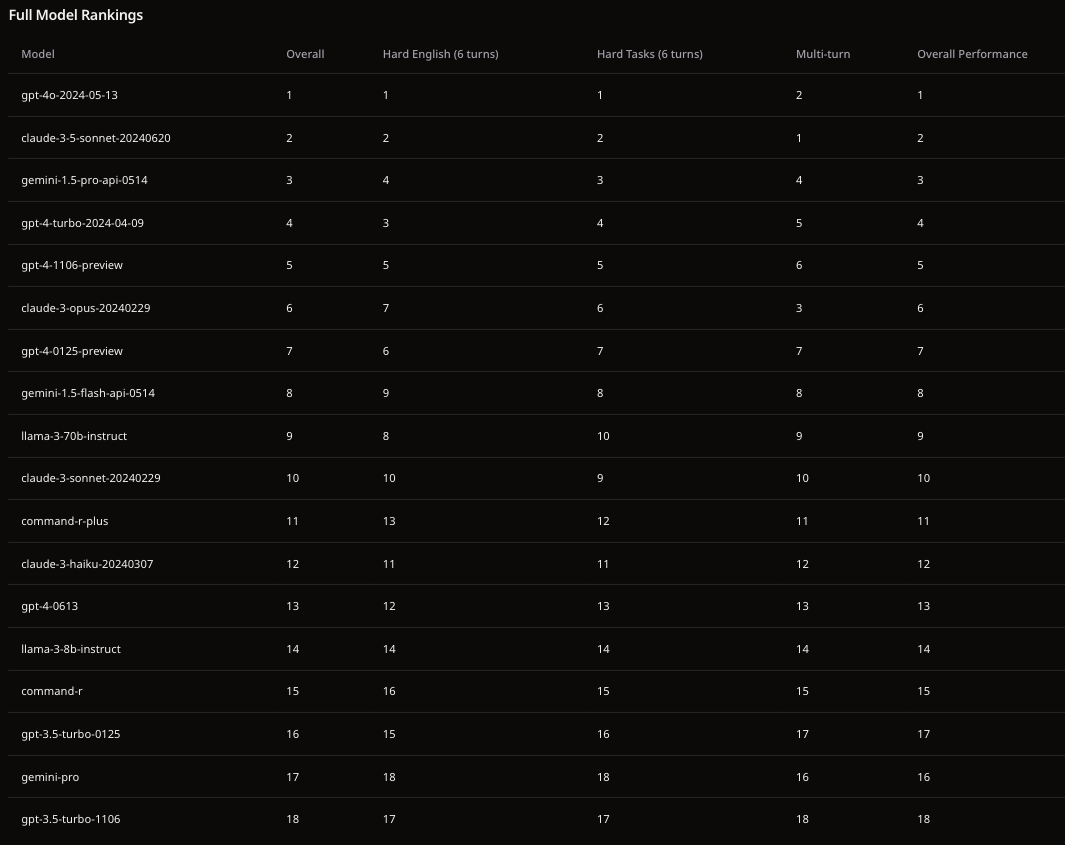 “PreCog Model Leaderboard by UbikAI” - this leaderboard is used by PreCog to match prompts with models based on the task at hand.
“PreCog Model Leaderboard by UbikAI” - this leaderboard is used by PreCog to match prompts with models based on the task at hand.
How does the Model Leaderboard work?
We rank the performance of select LLMs powering the Ubik AI platform's PreCog.
Rankings are based on over 1,000,000 human pairwise comparisons, evaluated using the Bradley-Terry model and displayed in a rank of Elo-scale. The dataset contains AI battles scored by humans and is maintained by Chatbot Arena (lmarena.ai) an open-source platform for evaluating AI through human preference, developed by researchers at UC Berkeley SkyLab.
Our evaluation focuses on a curated subset of models specifically used within the Ubik ecosystem, providing some insight into the capabilities behind PreCog.
PreCog lets you chat with the best models available so you get the most out of AI. Sign up today and start using models that suit to your problems.
Subscribe